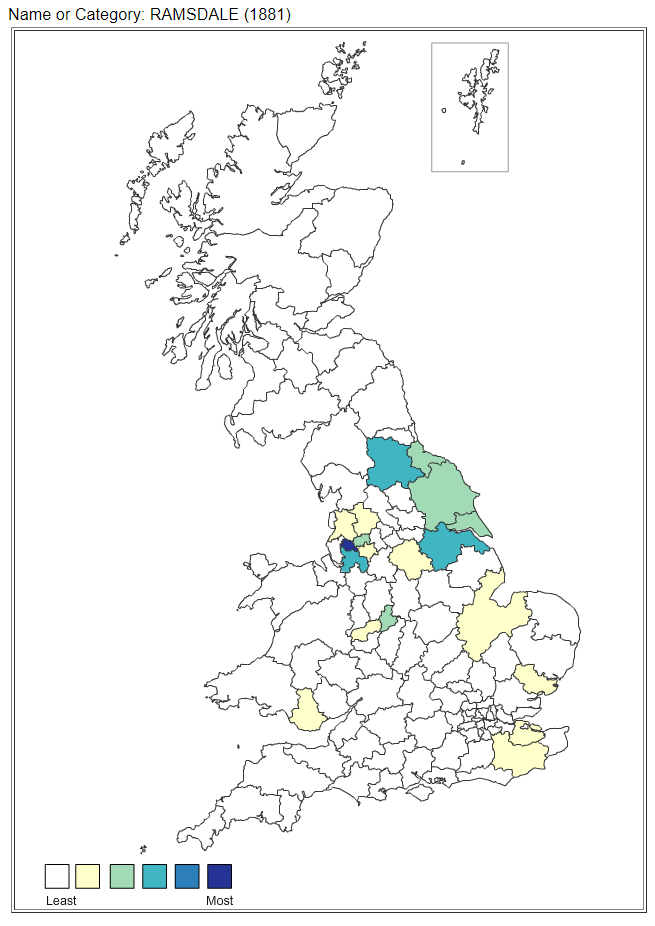
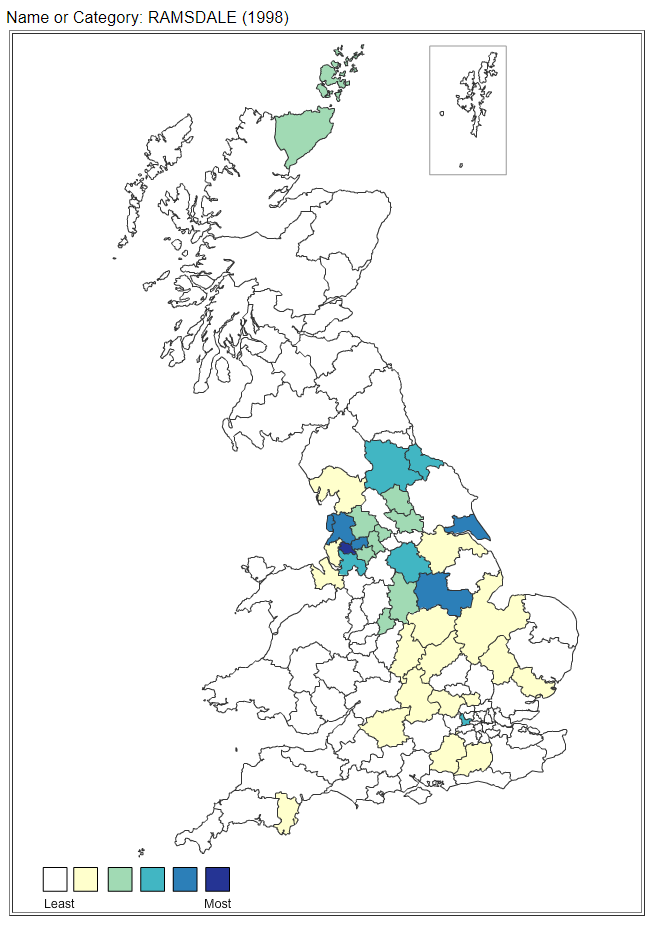
This page displays the outcome of a recent research project undertaken by the University College London (UCL) which has investigated the distribution of 25,630 family surnames in Great Britain, both current and historic, in order to understand patterns of regional economic development, population movement and cultural identity.
| Statistics about the surname RAMSDALE |
| Frequency |
1881 |
1998 |
Change |
| Frequency |
717 |
903 |
+186 |
| Rank Order |
5065 |
5638 |
-573 |
| Occurrences per million names |
27 |
24 |
-3 |
| International Comparisons |
| International Comparisons |
Rate |
As % of GB rate in 1998 |
| Great Britain Frequency (1998) |
929 |
100 |
| Great Britain Frequency (1881) |
717 |
|
| Great Britain Rate (1998) |
24 |
|
| Great Britain Rate (1881) |
27 |
|
| Northern Ireland |
0.0 |
|
| Republic of Ireland |
0.0 |
|
| Australia |
23.22 |
100.6 |
| New Zealand |
11.82 |
51.2 |
| United States |
1.75 |
7.6 |
| Canada |
10.19 |
44.2 |
| Geographical Spread |
| Geographical Spread |
Statistics |
| Great Britain top area (1881) |
Wigan |
| Great Britain top area (1998) |
Wigan |
| Great Britain top area index * |
2109 |
| Great Britain top postal town |
Wigan |
| Number of UK gazetteer entries |
1 |
| County of gazetteer entry |
North Yorkshire |
| Australia top state |
Tasmania |
| Australia top state index * |
399 |
| Australia top standard statistical division |
Kangaroo Island, South Australia |
| New Zealand top province |
Taranaki |
| New Zealand top province index * |
782 |
| United States top state |
Kansas |
| United States top state index * |
703 |
| Number of gazetteer entries in Africa or Asian |
none |
| Social Demographics |
| Social Demographics |
Statistics |
| Category of surname |
English - Locational Name; Settlement Ending; Dale |
| Mosaic type with highest index # |
High Technologists |
| Index of top Mosaic type * |
200 |
| % of people with a more rural name |
3 |
| % of people with a more high-status name |
67 |
| Cultural, ethnic, linguistic categories of surname |
English |
* Meaning of an 'index': An 'index' shows whether the level of something is higher in one area than it is in another area. In this instance UCL is interested in whether the number of occurrences of a name per million population is higher in a particular area than it is elsewhere. Thus UCL compares the incidence of a name in the US state where it is most concentrated with the average level of concentration in the whole of the US; the incidence in Australia's top state with the Australian average; the incidence in New Zealand's top province with the New Zealand average; the incidence in GB's top postal area with the GB average.
# Calculation of an 'index': If a name has a rate per million population in an area which is identical to its rate in a base comparison area then UCL says it has an index of '100'. An index of '200' for the name Jenson in Ohio would mean that the name Jenson was twice as common, per million population, in Ohio as it was in the reference area, in this case the whole US. An index of '500' for Wong in Victoria would indicate that the name Wong was five times more common per 1,000,000 names in Victoria than in the whole of Australia. An index of '1000' for the name Penhaligon in New Zealand would mean it was ten times more common per 1,000.000 names in New Zealand than in Great Britain. By contrast an index of only '50' would indicate a name which was only half as common in a target area than in its reference area.